
About Me
Data Scientist from Chicago with 5+ years experience in Data Analytics. I have a proven history of transforming data into business insights. I focus on optimizing operational processes to reduce costs and drive organizational success through strategic business analysis.
Skills
Programming Languages & Tools:
Python
• SQL
• R
• Scala
• Jupyter Notebook
• Git
• Markdown
• HTML
• CSS
Libraries:
Numpy
• Pandas
• Matplotlib
• Seaborn
• Scikit-Learn (Sklearn)
• TensorFlow
• Beautiful Soup
• Natural Language Toolkit (NLTK)
Machine Learning:
Classification
• Linear Regression
• Clustering
• Neural Networks
• Natural Language Processing (NLP)
• Web Scraping
Additional Tools & Software:
Jira
• OTM
• Oracle
• SAP
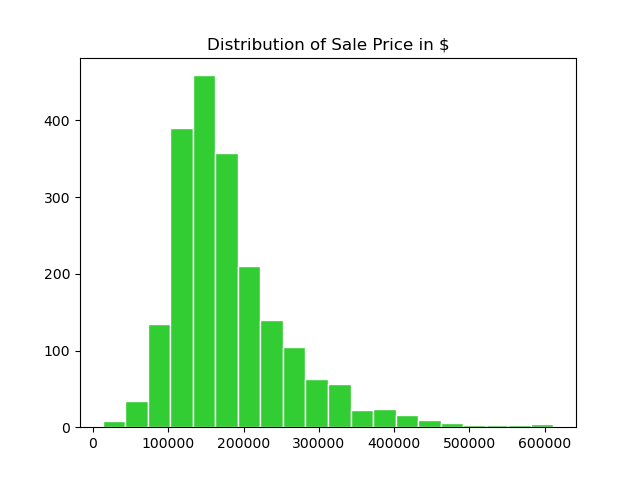
Predicting Housing Prices in Ames, Iowa
• Goal: Create a regression model to predict prices of houses in Ames, Iowa area.
• Key Objectives:
• Handle missing values
• Determine what each categorical value represents
• Identify outliers.
• Handle inconsistent categorical value frequency between train and test data.
• Consider whether discrete values are better represented as categorical or continuous values. (Are relationships to the target linear?)
• Key Accomplishments
• Cleaned all nulls without dropping any records
• Encoding categorical columns improved model by 9.2%.
• Used all numerical and categorical features through strategic encoding(dumbifying) and cleaning.
• Identified and handled mismatched categories between train and test datasets allowing us to carry out linear regression with no errors.
Model & Conclusion: Linear Regression
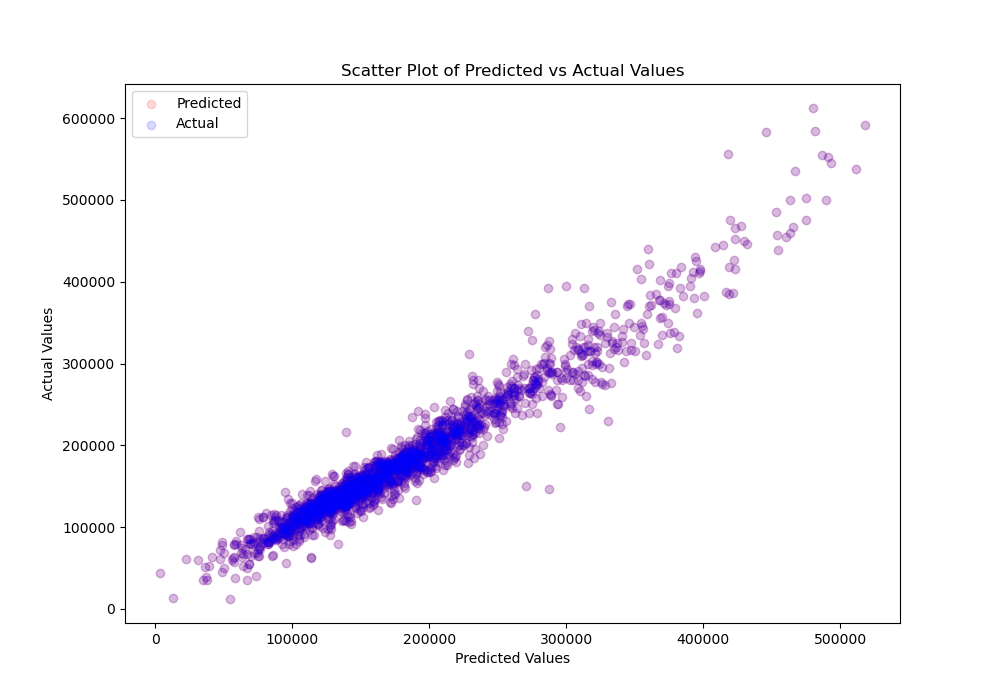
• Using all categorical and numerical features, linear regression model achieved a test accuracy score of 94.37%.
• Ridge, Lasso, gridsearch, standard scalar, and an outlier-removal-function were all tested but not used;
Linear regression alone yielded the best test results.
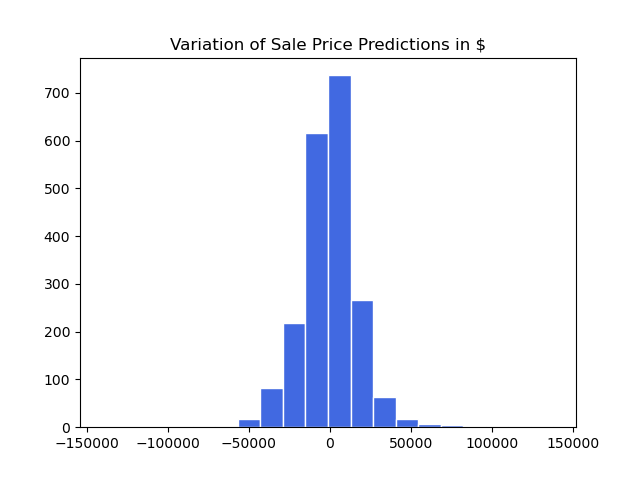
• Achieved a root mean squared error (RMSE) of $18,788.
This shows the model's predictions could be off by this amount at most.
Predicting Internet Service Subscription Cancellations
Goal: Create a classification model to predict wether a customer churn from a 72,274 customers dataset.
Key Objectives:
- Identify customer profiles that are likely to churn.
- Find a way to reduce overall churn rate.
- Reduce false negatives.
Modeling Improvements:
- Feature engineering: Created a new binary column "is_contract" that improved model score by 1%.
- Gridsearching over parameters improved model by 1%.
- Improved overall model score from 91.17% to 94.13%.
- Parameters used: learning_rate: 0.1, n_estimators: 150, max_depth: 7, max_features: log2.
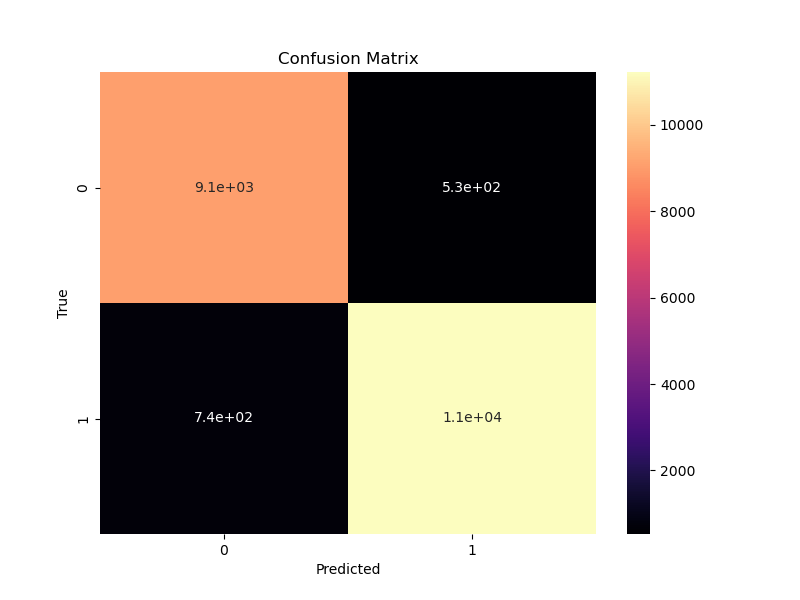
- Model predicted only 0.08% False Negatives (740 out of 9,100).
Key Accomplishments & Findings:
- Identified customers who had 2.5+ year contract with this ISP had less than 1% chance of churning.
- Through feature engineering, indentified customers with contracts churned less than 5% of the time.
- Customers with a TV subscription churned 10% of the time.
- Customers with Movie Package Subscription churned 34% of the time.

Conclusion: The best model was a gradient boost classifier with gridsearched parameters which achieved a test accuracy score of 94.13%.
Subreddit Classification
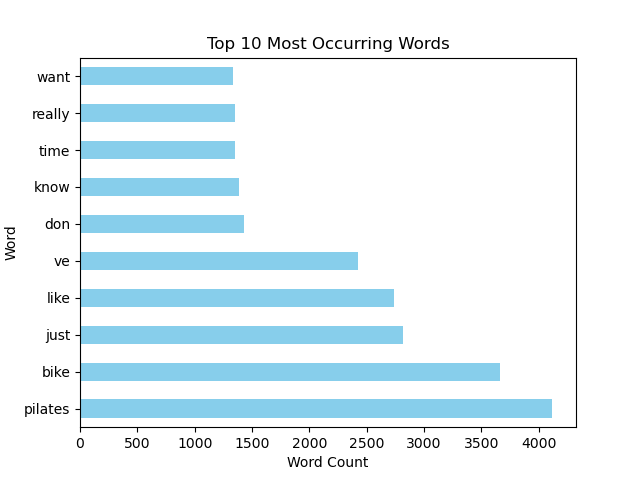
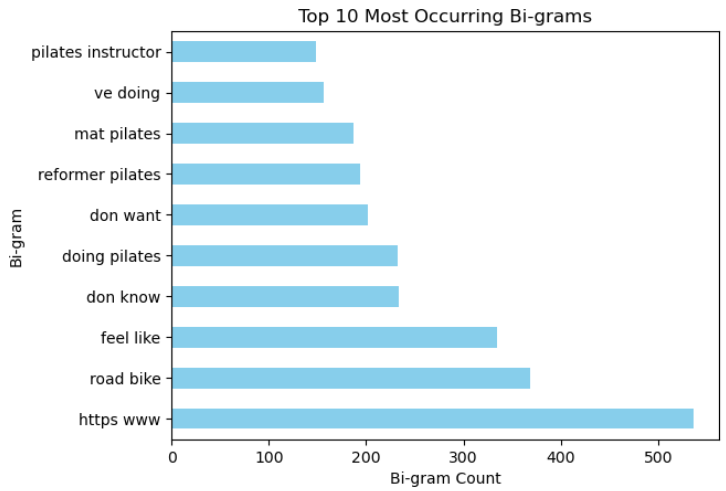
Goal: Create a classification model to predict the subreddit a post came from using NLP.
• Collected 7,000+ articles from the r/pilates and r/cycling subreddits using the Reddit API.
• Regular expressions were used to clean the data and multiple classification models employing NLP techniques were created to determine the subreddit to which the titles and posts belonged.
Key Accomplishments
• Natural language processing (NLP) techniques such as tokenization, stop word removal, stemming and lemmatizing were employed as pre-modeling and exploratory data analysis (EDA) steps.
• Of 3 different classification models initially attempted, the best model was selected for hyperparameter tuning using grid searching.
Conclusion: The best model was a logistic regression classifier with gridsearched parameters which achieved a test accuracy score of 99.33%.
• It was speculated that the vastly different subject matter of the two subreddits may be the cause for such a high accuracy score not the model itself.
• The model proves to eliminate false positives over 99% of the time.
• Using the scraping function developed, we can pull articles from any subreddit and test these models for further analysis with different subject matter.
Contact Me
If you have a project you'd like to collabroate on or would like to talk about an idea you have, shoot me a message. Thanks!